-
[OS101] 프로세스테크 2023. 9. 10. 15:47

본 글은 2023.09.10에 새롭게 업데이트되었습니다.
서울대학교 평생 교육원에서 제공하는 운영체제의 기초 강의 내용을 중점으로 정리했다. 부족한 부분은 <Operating System Concepts> 책을 참고하면서 채워 나갔다. 이해를 돕기 위한 그림들은 여기에서 가져왔다.
목차
- 프로세스란 무엇인가
- 프로세스 구현 방법
- 프로세스 스케줄링
- 프로세스 생성 및 종료
프로세스란 무엇인가
프로세스(process)는 운영 체제가 CPU, 메모리, I/O 디바이스를 할당하는 주체이다. 즉, 실행 중인 프로그램(program in execution)이다. 프로그램은 저장 매체에 저장된 명령어들의 집합체이기 때문에 수동적인 반면, 프로세스는 운영체제에 의해 저장 매체로부터 읽어져 메인 메모리에 로드된 후 CPU와 같은 자원을 능동적으로 사용하는 수행 주체이다. 또한 프로세스는 메모리 컨텍스트, 하드웨어 컨텍스트, 시스템 컨텍스트 위에서 수행되는 실행 흐름(execution stream 또는 thread of control)이라 할 수 있다.
- 메모리 컨텍스트(Memory Context): 코드(code), 데이터(data), 스택(stack), 힙(heap)을 일컫는다.
- 하드웨어 컨텍스트(Hardware Context): CPU 레지스터, I/O 레지스터 등을 일컫는다.
- 시스템 컨텍스트(System Context): 프로세스 테이블, 오픈 파일 테이블, 페이지 테이블 등을 일컫는다.
프로세스 구현 방법
프로그램은 데이터 구조와 알고리즘으로 구성되어있다고 봐도 무방하다. 따라서 프로그램의 인스턴스인 프로세스가 어떤 식으로 구현되어 있는지 알기 위해서는 해당 데이터 구조와 알고리즘을 자세히 살펴보는 것이 중요하다.
- 데이터 구조 측면: PCB
- 알고리즘 측면: 프로세스 라이프 사이클
데이터 구조 측면: PCB
PCB(Process Control Block)은 한 개의 프로세스에 관련된 정보들을 담고 있는 데이터 구조이다. 현재 대부분의 컴퓨터는 여러 개의 프로세스에 의해 CPU가 다중 사용이 되고 있다. 이 때문에 PCB를 효율적으로 관리하기 위해서 연결 리스트(linked-list)로 만든 테이블인 프로세스 테이블(process table)이 존재한다. 그렇다면 PCB에 정확히 어떠한 정보가 담기는지 살펴보자.

PCB - 프로세스 상태 (Process State): New, Ready, Running, Waiting, Halting 상태를 담고 있다. 이에 대한 내용은 아래의 '알고리즘 측면: 프로세스 라이프 사이클'에서 설명한다.
- 프로세스 번호 (Process Number): 프로세스 번호를 뜻한다. 각 프로세스는 고유한 번호를 가지고 있다.
- 프로그램 카운터 (Program Counter, PC): 다음에 실행될 명령어의 주소를 가리킨다.
- 레지스터 정보: 프로세스가 실행될 때 사용하고 있는 레지스터에 대한 정보를 가지고 있다.
- CPU 스케쥴링 정보: CPU 스케쥴링에 필요한 프로세스의 우선 순위 등에 대한 정보를 담고 있다.
- 메모리 관리 정보: 베이스 레지스터(base register), 경계 레지스터(limit register), 페이지 테이블, 세그먼트 테이블(segment table) 등의 정보를 담고 있다.
- I/O 상태 정보: 프로세스에 할당된 I/O 디바이스들에 대한 정보를 가지고 있다.
- 오픈 파일 정보: 오픈 파일 리스트 등을 포함한다.
알고리즘 측면: 프로세스 라이프 사이클
아래의 그림은 굉장히 유명한 다이어그램으로, 프로세스의 동작 과정을 한눈에 볼 수 있는 좋은 자료이다. 프로세스 라이프 사이클이라고 부르기도 한다. 해당 다이어그램을 하나하나씩 뜯어보자.
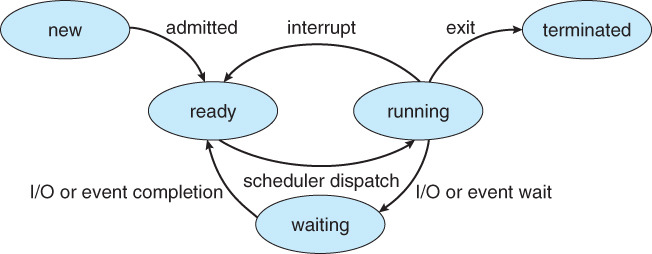
프로그램 라이프 사이클 파란색 동그라미는 프로세스가 가질 수 있는 상태(state)를 뜻한다. 그리고 검은색 화살표는 상태-상태 간 전이(state-to-state transition)를 뜻한다.
프로세스 상태
- new: 프로세스가 생성된다.
- ready: 프로세스가 CPU에 할당되기를 기다리고 있다. 이 때 프로세스들은 레디 큐(ready queue)에서 대기 중이다.
- running: 명령어들이 실행되고 있는 중이다.
- waiting: 프로세스가 I/O 완료와 같은 이벤트가 일어나길 기다리고 있다. 기다리는 목적에 따라 별도의 큐가 존재한다.
- terminated: 프로세스의 실행이 종료된다.
상태-상태 간 전이
- new → ready (admitted): 프로세스 생성이 완료된 후 커널에 프로세스를 등록한다.
- ready → running (scheduler dispatch): CPU 스케줄러에게 선택받은 프로세스는 디스패처(dispatcher)에 의해 컨텍스트 스위칭(context switching)되어 running 상태로 진입한다. 이에 대한 설명은 뒤에서 자세하게 설명한다.
- running → ready (interrupt): 선점적 스케줄링(preemptive scheduling)에 의해서 발생한다. 이는 하드웨어 인터럽트에 의해서 발생하며 CPU 스케쥴러가 개입하여 CPU를 빼앗은 것이다.
- running → waiting (I/O or event wait): 비선점적 스케쥴링(non-preemptive scheduling)에 의해서 발생한다.
- running → terminated (exit): 비선점적 스케쥴링에 의해서 발생한다.
- waiting → ready (I/O or event completion): 선점적 스케쥴링의 일부분이다. 비동기적(asynchronous)인 이벤트가 발생해야 한다.
선점적 스케줄링과 비선점적 스케줄링은 CPU 스케줄링 파트에서 자세히 설명하겠다.
프로세스 스케줄링
프로세스 스케줄링의 목적은 각 프로세스들이 공평하게 CPU를 공유할 수 있도록 하는 것이다. 이때 스케줄러는 정책(policy)과 메커니즘(mechanism)으로 이루어져 있다. 여기서 정책이란 다음에 수행할 프로세스를 선택하는 기준이며, 이에 대해서는 CPU 스케줄링 파트에서 자세하게 다룬다. 메커니즘은 CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 것을 뜻하며, 지금부터 이 메커니즘을 수행하는 디스패처(dispatcher)에 대해서 자세히 알아보도록 하겠다. 그리고 컨텍스트 스위칭이 무엇인지 어떻게 일어나는지에 대해서 알아보겠다.
- 디스패처
- 컨텍스트 스위칭
디스패처
디스패처는 유저 프로세스 A와 유저 프로세스 B가 수행되는 중간에 개입을 해서 CPU를 A에서 B로 넘겨주는 역할을 한다. 디스패처는 커널 모드에서만 실행이 되는데, 어떻게 호출되어 동작하는 것일까? 바로 인터럽트에 의해서 호출된다. 프로세스 A가 실행되고 있을 때 모종의 이유로 인터럽트가 걸리게 되면, 인터럽트 서비스 루틴(interrupt service routine)이 호출되고 커널 모드로 바뀐다. 그리고 커널 함수의 일종인 디스패처를 콜 한다. 디스패처는 선점적 또는 비선점적 CPU 스케줄링에 의해서 호출된다. 정리하면 다음과 같다.
- 유저 프로세스 A가 수행되고 있다.
- 선점적 또는 비선점적 CPU 스케줄링에 의해서 인터럽트가 걸린다.
- 인터럽트 서비스 루틴이 뜬다.
- 인터럽트 서비스 루틴은 모드를 뜻하는 PSW(Process Status Word)를 0으로 바꾼다.
- 커널 함수의 일종인 디스패처가 호출된다.
- 프로세스 A의 컨텍스트가 안전한 곳으로 대피된다.
- 프로세스 B의 컨텍스트가 로드된다.
- 인터럽트 서비스 루틴이 끝난다. (그리고 모드도 유저 모드로 바뀐다.)
- 유저 프로세스 B가 수행된다.
컨텍스트 스위칭
컨텍스트 스위칭은 현재 수행 중인 프로세스의 컨텍스트-상태, 코드, 데이터, PCB 등-를 안전한 곳에 대피시키고 다음에 수행될 프로세스의 컨텍스트를 불러오는 작업을 뜻한다. 디스패처는 컨텍스트 스위칭을 일으킨 후, 다음에 수행될 프로세스에게 CPU를 넘겨주는 모듈(또는 함수)이다.
WHAT 어떠한 컨텍스트를 대피시켜야 할까? 하드웨어 컨텍스트는 반드시 메인 메모리로 대피해야 한다. 시스템 컨텍스트는 CPU 수행과는 관련 없는 요소이기 때문에 대피할 필요가 전혀 없다. 메모리 컨텍스트를 대피시키는 방법은 3가지이다. 첫 번째는 대피를 아예 하지 않는 것이다. 두 번째는 전부 대피하는 것이다. 이 경우 디스크로 모든 메모리 컨텍스트가 옮겨져야 한다. 현재 수행 중인 프로세스가 CPU를 빼앗기면 디스크 스와핑(roll out, roll int)을 해야 하는데 이는 매우 느리다. 마지막으로 메모리 컨텍스트의 일부만 대피하는 방법이다. degree of multiprogramming이 너무 큰 경우에는 스와핑이 많이 일어나서 성능 저하가 일어날 수 있지만 현재까지는 그나마 괜찮은 방법이기 때문에 세 번째 방법이 쓰이고 있다.
WHERE 어디로 컨텍스트를 대피시켜야 할까? 바로 커널 스택이다. 일반적으로 유저 모드에서의 함수 콜은 유저 스택에 쌓인다. 그러나 커널 모드 때의 시스템 콜은 커널 스택에 쌓인다.
HOW 자 그렇다면 이제 어떻게 컨텍스트 스위칭이 일어나는지 알아보자.

커널 스택 구조 위의 그림은 커널 스택의 구조이다. 스택은 위에서 아래로 자란다. 설명에 앞서 스택 명령어에 대해서 알아보자. PUSH는 는 스택으로 안전하게 대피하는 명령어이다. POP은 스택의 내용을 다시 레지스터로 옮기는 복구 명령어이다. CPU의 레지스터 중에서 SP(stack pointer)가 존재한다. 이 레지스터는 현재 수행 중인 프로세스 스택의 탑(top) 주소를 가리키고 있다. 또한 OSPCBCur라는 전역 변수는 현재 수행 중인 프로세스의 PCB를 가리키고 있다. PCB에는 컨텍스트 스위칭에 필요한 정보인 스택 포인터 필드(Stack Pointer Field, StkPtr)가 있다.
아래는 컨텍스트 스위칭 동작 과정을 설명하기 위한 예시 명령어이다. 프로세스 A의 0x100번지에 있는 명령어를 수행하고 있는 중에 인터럽트가 발생한 상황이다. 그리고 어떻게 프로세스 B로 넘어가는지 살펴보자.
프로세스 A
0x100 ADD r0, r1, rx ← ADD 오퍼레이션 수행 중, 인터럽트 발생
0x104 next instruction프로세스 B
0x200 ~ ← 프로세스 B가 수행을 시작한다면, 제일 먼저 실행되어야 할 명령어- CPU는 프로세스 A의 ADD 명령어 수행을 끝낸다.
- 인터럽트가 발생했는지 체크한다.
- 인터럽트가 발생했다는 것을 인지한다.
- 하드웨어의 서포트에 의해서 현재 PSW를 커널 스택에 PUSH 한다.
- 하드웨어의 서포트에 의해서 PC 값(= 리턴 어드레스 값, 0x104)을 커널 스택에 PUSH 한다.
- 어떠한 인터럽트가 걸렸는지 알기 위해 IRQ를 확인한다.
- 인터럽트 벡터 테이블을 이용해서 해당 ISR 시작 주소를 찾은 후 점프한다.
- ISR 초반부에 PSW 값을 0으로 바꾼다.
- 디스패처를 호출한다.
- PUSHA 명령어를 이용해서 CPU 레지스터들을 커널 스택에 차례로 PUSH 한다.
- SP는 계속 변하므로 스택에 저장된 SP는 더 이상 의미 없는 값이다. 그래서 제대로 된 값을 프로세스 A의 PCB의 StkPtr에 넣어준다.
- 스케줄러를 호출하여 다음에 실행될 프로세스가 무엇인지 알려준다. (프로세스 B)
- OSPCBCur는 프로세스 B의 PCB를 가리킨다.
- CPU의 SP 레지스터에 OSPCBCur→StkPtr로 세팅한다.
- POPA 명령어를 통해서 프로세스 B의 컨텍스트를 CPU 레지스터에 채워 넣는다.
- PSW 값을 유저 모드인 1로 복구시킨다.
- ISR 수행의 마지막에 return from interrupt 명령어를 수행한다.
- 프로세스 B의 0x200이 작동을 시작한다.
여기서 디스패처는 9-17 부분을 수행한다. 최초로 컨텍스트 스위칭이 발생할 땐, 페이크 스택을 만들어 주어서 한 번이라도 컨텍스트 스위칭이 일어났던 것처럼 해주어야 한다. 이러한 페이크 스택은 프로세스 별로 한 개씩 가지고 있으며 메인 메모리에 상주한다.
프로세스 생성 및 종료
- 프로세스 생성
- 프로세스 종료
프로세스 생성 (Process Creation)
프로세스가 생성되기 위해서는 프로그램이 디스크 내에 있어야 한다. 이 프로그램을 실행 파일(executable file)이라고 한다. 실행 파일의 경로(path)가 운영 체제에 전달되고, 운영 체제는 코드 영역과 데이터 영역을 읽음으로써 실행 파일을 로드한다. 프로세스의 정보를 PCB에서 가져온 후 malloc()을 해서 동적할당하여 생성한 후 레디 큐에 담는다. 유닉스 계열은 PID(프로세스 아이디)가 0인 경우만 이러한 작업을 하고 나머지 프로세스는 fork() 시스템 콜을 이용하여 복제(cloning)한다.
- 부모 프로세스 (Parent Process): 기존의 프로세스
- 자식 프로세스 (Child Process): 부모 프로세스로부터 만들어진 새로운 프로세스

프로세스 생성 과정 부모 프로세스가 자식 프로세스를 만들기 위해서 fork()를 호출한다. 운영 체제는 fork()를 호출한 부모 프로세스를 완전히 중단시킨 후 해당 프로세스가 가지고 있는 컨텍스트들의 스냅샷을 찍는다. 스냅샷 찍은 그대로 자식 프로세스에게 카피가 된다. 자식 프로세스의 PCB에 들어가는 PID 값을 제외한 다른 값들은 부모 프로세스와 완전히 같다. 그리고 자식 프로세스의 PCB를 레디 큐에 보내면 fork() 수행은 끝나서 다시 부모 프로세스로 리턴된다.
이런 방식은 한 가지 의문점을 남긴다. 하나의 동일한 프로그램만 돌릴 수 있는가..? 말도 안 된다. 따라서 fork()를 한 후 반드시 exec()라는 시스템 콜을 호출해야 한다. exec() 함수를 통해 새로운 프로그램의 코드와 데이터를 오버라이트 할 수 있게 된다. 이 방법도 사실 문제가 많다. 부모 프로세스로부터 전부 복사해 왔는데 무시하고 덮어쓰기 때문이다.

COW-1 
COW-2 위 그림은 UNIX에서의 프로세스 생성 과정이다. 부모 프로세스가 fork()를 하면 그 시점부터 컨텍스트가 복제된다. 그 후 exec() 수행을 하면 부모 프로세스와 자식 프로세스는 다른 동작을 수행하게 된다. 부모 프로세스는 자식 프로세스가 종료되기까지 wait() 상태에서 기다린다. 이때, wait() 인자는 자신이 생성한 자식 프로세스의 PID이다. 이 때 부모 프로세스가 반드시 wait()를 호출하지 않아도 된다. 자식 프로세스에서 exit()이 수행되면 프로세스가 가지고 있던 자료 구조나 자원들을 운영 체제가 전부 회수해간다. exit()을 마친 프로세스를 좀비 프로세스(zombie process)라고 하며, exit()을 마치고 부모 프로세스가 자신의 exit status를 읽어가기를 기다리는 상태를 좀비 상태라고 한다.
#include <stdio.h> #include <unistd.h> #include <sys/types.h> int main() { pid_t pid; int x = 0; printf("Before fork()\n"); pid = fork(); if(pid > 0) { // parent process x = 1; printf("Parent PID: %ld, x: %d , pid: %d\n",(long)getpid(), x, pid); } else if(pid == 0){ // child process x = 2; printf("Child PID: %ld, x: %d, pid: %d\n",(long)getpid(), x, pid); } else { // fails fork() printf("Fork Fail.\n"); return -1; } return 0; }위 코드는 부모 프로세스가 자식 프로세스를 생성하는 프로그램이다. fork()가 성공할 경우 자식 프로세스의 PID가 부모 프로세스에게 리턴되며, 자식 프로세스에게는 0이 리턴된다. 포크에 실패할 경우 -1이 리턴되며, 적절한 errno 값이 설정된다. 주의할 점은 fork()의 리턴 값이 실제 PID를 뜻하는 것이 아니라는 점이며, 자식 프로세스의 PID는 반드시 1 이상이다.

실행을 시켰을 때 출력되는 결과를 살펴보자. Before fork()는 단 한 번만 뜬다는 사실을 알 수 있다. fork() 함수에 의해서 포크될 때, 부모 프로세스의 모든 컨텍스트가 복사되기 때문에 자식 프로세스도 이미 fork() 함수를 실행하고나서의 컨텍스트를 가지고 있다. 그렇게 After fork()는 두 번 실행되는 것이다. 부모 프로세스의 PID는 24763번이고 자식 프로세스의 PID는 24764이다. 부모 프로세스에서 pid 변수에는 자식 프로세스 값이 들어있기 때문에 24764가 출력된 것이고, 자식 프로세스에서 pid 변수에는 0이 들어가있기 때문에 0이 출력된 것이다.
그렇다면 왜 이런 식으로 자식 프로세스를 형성하게 되었을까? 초창기 유닉스에서는 프로세스 간 통신(IPC)을 할 수 있는 방법이 fork() 뿐이었다. 당연히 부모 프로세스와 자식 프로세스만 서로 통신할 수 있다. 이러한 통신 문제를 간단히 해결하기 위해 fork()와 exec() 메커니즘이 개발된 것이다. 자식 프로세스가 부모 프로세스를 카피한 후 exec()으로 바로 오버라이트 하는 문제를 COW(Copy On Write)로 해결한다. COW는 부모 프로세스 컨텍스트를 fork() 시점에서 복사하지 않고, 새로운 값이 쓰일 때 복사하는 기법이다. 그래서 사실상 불필요한 카피나 성능 저하는 거의 없어졌다.
프로세스 종료 (Process Termination)
프로세스 수행을 종료하는 방법은 두 가지가 있다.
- 정상적인 exit()을 호출해서 종료하는 방법이 있다.
- 비정상적으로 자신이 잘못했을 때, 부모 프로세스가 kill 한다. 이는 abort()하거나 signal을 보내서 종료시킨다.
'테크' 카테고리의 다른 글
[Swift] Foundation에서 제공하는 동기화를 위한 Lock에 대해서 알아보기 | NSLock | NSRecursiveLock | NSConditionLock | NSCondition | NSDistributedLock (1) 2023.10.25 [OS101] 쓰레드 (0) 2023.09.14 [OS101] 운영 체제를 이해하기 위한 컴퓨터 구조 기초 (4) 2023.09.05 [OS101] 운영체제 역사 및 기능 (0) 2023.09.05 [WWDC21] Mitigate fraud with App Attest and DeviceCheck (0) 2023.08.17